____| \
| | | _ / _ / _ \ __| _ \ __ `__ \ _ \ __| _ \
__| | | / / __/ | ___ \ | | | ( | | __/
_| \__,_| ___| ___| \___| _| _/ _\ _| _| _| \___/ _| \___|
June 8, 2025
Fuzzer Amore - iOS fuzzer
Introduction
Hello,
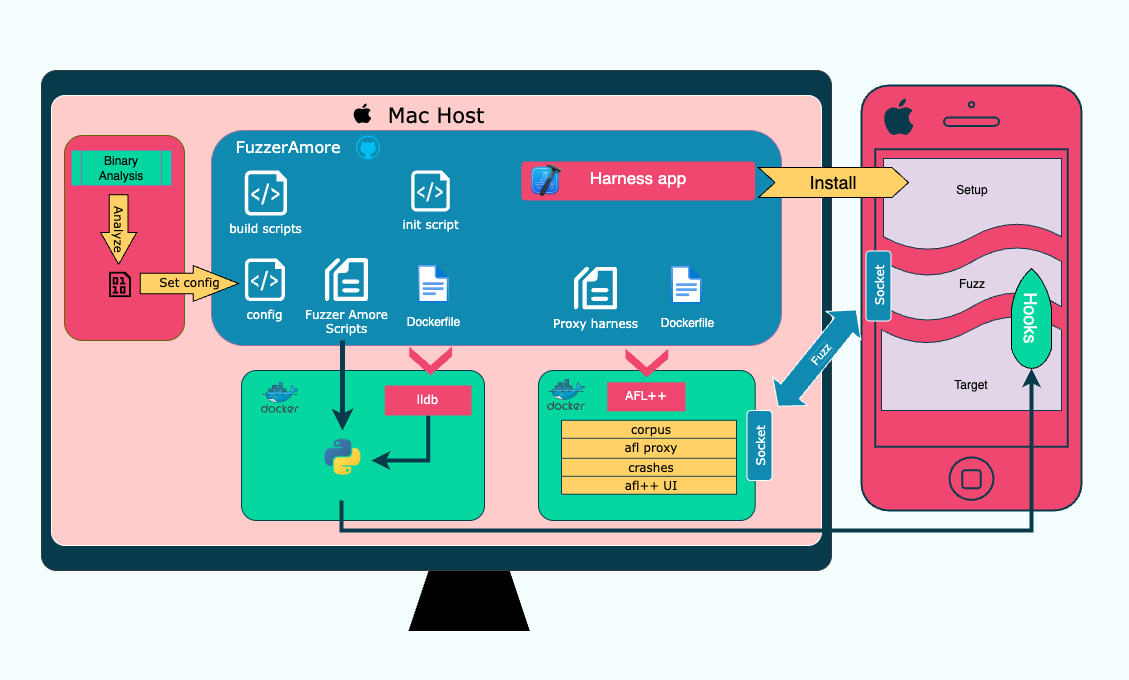
In this second post I will be presenting Fuzzer Amore - an iOS-on-device
fuzzing setup that connects an AFL++ fuzzer running on the Mac to a harness on the iOS device without the need of a jailbroken device.
This limits fuzzing to code executed within your process, but includes the ability to fuzz user-space OS libraries or other imported libraries,
and can run on the latest iOS version
This project does not rely on the iosEnv setup, yet, since this setup uses containers, some of the concepts are similar. Read the post if you haven't, or if you want to learn more about the port forwarding, iproxy usage, and lldb patch that are used in this project.
fpicker
As an iOS researcher, a field in which information is not common on the public domain, and literature is somewhat narrow compared to Windows, for example, the learning process of new concepts always starts with popular projects that support, well, Windows, Linux, Android, Mac, and on a lucky day - some support for an older version of iOS.
My first interaction with fuzzing was no different, as I followed the introductory tutorials by Google, AFL, etc.
Further search led me to fpicker by Dennis Heinze - a Frida based iOS fuzzing setup that utilizes AFL's proxy mode, and uses Frida to send the input to the fuzzing target, and also to instrument the code coverage so that AFL can change the inputs accordingly.
As many former managers told me: "no need to reinvent the wheel", I gave it a try, yet, encountered some issues:
- It hasn't been maintained in a while
- I wanted to run on a physical device, yet encountered this error message that AFL fuzzer mode is not supported over USB and/or a remote device
- Even if I managed to get it working, performance would likely remain slow over USB/LAN/Wifi
And yet, as an experiment, I wanted to still make it work. I read the wonderful fpicker blog post by its author, and used the afl++'s proxy example, and created a small afl++ proxy inside in a container based on their official docker.
This c proxy sent AFL's inputs via a socket to a Python script, which also initiated Frida, and hooked to the fuzzed function, and, using a similar Frida agent, created coverage info and passed it back to the socket of the c proxy, which reported the coverage to afl
This worked well, but as expected, performance was slow (< 100 exec/sec), due to all the overheads
lldb to the rescue
Trying to list the performance factors, Frida over USB and the data conversions were the ones I could try to get rid of
The fastest ways I know for executing code are C and ASM. Frida C module was indeed an option, yet I still had to convert buffers and have Python as a mediator
LLDB ended up to be my choice, mainly because I know it pretty well, it can write ASM instructions, but most importantly: it can run on a jailed device with any version, and it can detach while leaving all the memory changes it made in place
After setting up everything, AFL showed ~350 exec/sec.
ASM Hooks
lldb could not malloc a buffer and run code on it, probably due to the W^X limitation. Yet, since I am writing the harness app I can setup executable regions (plain code)
There might be more sophisticated ways of doing it, but I simply wrote a long function filled with code that isn't meant to run, yet it will be added to the binary
Then, lldb can locate its symbol and set that up as if it was an executable regions playground that it can freely write code to
- (void)myCodePlayground {
NSString* playground = @"My Playground";
int i = 0x10;
NSLog(@"%@ %d", playground, i);
i++;
NSLog(@"%@ %d", playground, i);
i++;
NSLog(@"%@ %d", playground, i);
i++;
// and so on...
}
The concept is that each end of a basic block gets its own destination space in the playground.
LLDB reads the mnemonics between two addresses, and replaces the ones that mark the end of a basic block with a B (branch) to the dedicated address
The following diagram illustrates a single edge hook example:
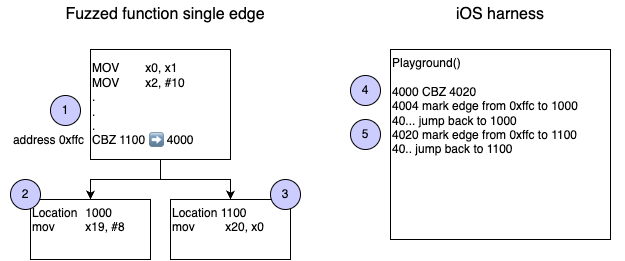
Address 0xffc, marked
The address, on the other hand, needs to change for reporting the edge.
Branching to 4000 invokes the playground hook, which starts with the condition,
and either skips to the next instruction in the playground, or to another address the playground (for example 4020 at
The Python script is also responsible for writing the instructions of each case inside the playground:
In case the register was zero, CBZ will now jump to 4020 instead of 1100.
If the register was non zero, it will skip to 4004, instead of skipping from 0xffc to 0x1000.
For now, let's assume that the reporting part contains a few opcodes (explained on the next section),
and as they end, the code branches back to the block it should have jumped to without the playground hook.
ie, if the register was zero branch back to 1100 and if not, to 1000.
Reporting an edge
The code in each block of the playground is responsible for reporting the addresses of the original edge,
and jump back to execute the next block. This code should also preserve the registers after it is done.
To minimize the assembly code that needs to be written at each hook, the code simply calls an
existing function in the iOS harness:
-(void)reportEdge:(void*)from to:(void*)to {
@autoreleasepool {
[map addObject:[NSArray arrayWithObjects:[NSNumber numberWithUnsignedLong:from], [NSNumber numberWithUnsignedLong:to], nil]];
}
}
Yet again, lldb can find this symbol and use its address to call the function, which is performed on each playground block.
Calling the
- X0 contains self (ie, the ViewController)
- X1 contains the address of the report edge method
- X2 contains the first parameter (the from address)
- X3 contains the second parameter (the to address)
The playground block stores the previous values of x0-x3, uses these registers as per the list above, branch-links to the report function, restores the registers values, and jumps back to the original basic block verdict.
Playground Final State
The script finishes writing all the hooks, and the playground ends up containing edge reporting blocks for each branching of the original call tree
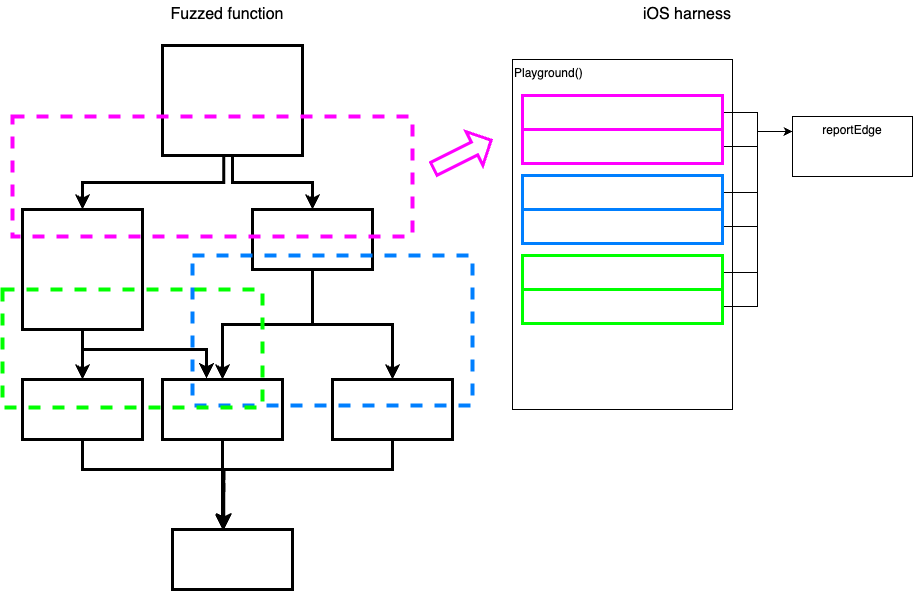
Recap So Far
In Logical Order
AFL++ runs in proxy mode, meaning it sends input to a small C program, and expects
coverage information of each input.
The C program sends these inputs via a socket to a local port.
An iOS harness installed on the device using Xcode. This harness listens to the same port for receiving inputs.
Upon setup, lldb-python scripts places hooks on the fuzzed function (that is pre-configured) which collect coverage data.
Once the hooks are in place, lldb is detached from the process to prevent latency, yet the hooks remain.
When the function exits the coverage data is sent back via the socket to the C harness, and back to AFL++ in the expected format
In Chronological Order
While the previous paragraph makes sense logically, setting and running the fuzzer is done in different order.
First thing, you select your fuzzed function and set its addresses. You should analyze the function statically
to see that it matches fuzzing criteria, and in addition, that the playground has enough space for the number of edges.
A thumb rule for calculating the size can be found in the iOS harness comment above
Next step is installing the iOS harness on the device using Xcode. Once installed you don't need Xcode anymore, unless you need to debug something.
Next, run the iOS harness, which will start listening to the port.
Then, run the LLDB Docker container, which sets up ports, creates a tunnel to the device (assuming iOS 17+), finds the harness PID, start lldb server,
connects lldb client to the process, places the hooks, and confirms that the hooks were placed.
Now, continue running the app, detach the debugger, quit lldb, and exit the docker.
Finally, run the AFL++ docker, which sets up ports, compiles the C harness, creates random corpus,
and initiates the fuzzing (and its UI)
Trampoline
When using the playground to instrument a local function, it is safe to assume that the
distance between the fuzzed function
and the playground is within 50Mb. When fuzzing system libraries, or third party libraries,
the loader may place them further apart. In such case, branching from the end of the basic block to the playground
using a single opcode does not work.
The previously explained concept, of replacing the split mnemonic with a single jumping instruction, is limited by arm64
syntax, which allows
Replacing, monitoring, and reconstructing more than one opcode per split could become complex, hence, another solution was implemented.
A new zone, named Trampoline, will be defined by the user, and the hooks will branch to it before jumping again to the playground.
The zone must be executable, close enough to the fuzzing target, and out of the calling scope of the fuzzed function,
as we are about to re-write the instructions in that zone.
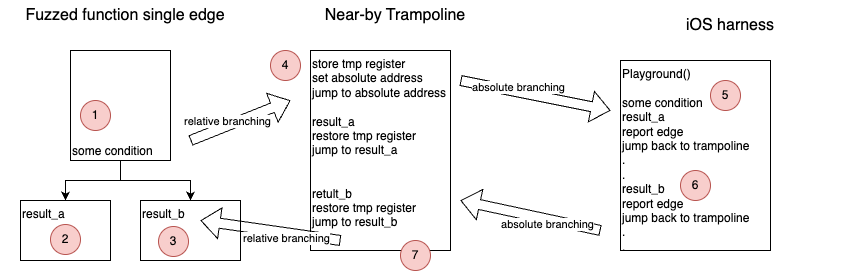 Consider the diagram above. The fuzzed function has a condition split
Consider the diagram above. The fuzzed function has a condition split
The playground
Now, let's assume the condition resolves to result_b. In this case the playground jumps to a relative
address
Networking
The TCP packets from this host port are forwarded to another local port, also configured in the same file,
which is mapped using iProxy to the same port on the device.
The second channel is the secure tunnel that Apple started requiring starting iOS 17 to start the debugserver on the device.
Creating this tunnel must be performed as sudo, which is why the
The tunnel uses ipv6 and returns the information that lldb needs for attaching to the debugserver. If you end up changing this script, just pass the result to the Python script that performs the connection.
Lastly, using libmuxd is used for obtaining the PID of the iOS harness. While it is possible to use pymobiledevice3 for this task,
I am using libmuxd since it is assumed it is already installed on the host (which is the case if iproxy is set up, as far as I recall.
libmuxd uses a unix socket on the host to communicate with the USB interface. This acts as a buffer path,
allowing read and write operations. The container is not aware of the physical USB interface of the host, and so, we use a host port to
communicate between the host's unix socket to the container's unix socket. While it may be possible to do it using folder sharing, latency
is irrelevant here because we are just writing the hooks and not running the fuzzer yet.
tools
socat is used for doing the needed port forwarding.
netcat is used for finding the pids of the previous run that may still occupy our configured ports and kills these processes
iproxy, libmuxd, pymobiledevice3 are used for the container-host-device communications and actions.
Crashing
AFL is sending multiple inputs per second, trying to cause the process to crash. However, the iOS harness should report this crash to AFL and ideally prevent the application from crashing so that AFL will be able to log multiple crashes in a single run.
The C harness is set up to count and save each crash, even if it is similar to a previous one.
When stopping the fuzzer with multiple crashes, expect many of them to have the buffer similarities.
It is possible to configure this in the C harness if you search for
The results are saved on the outputs folder inside the AFL container. Make sure to either mount the folder
to a folder on your host or copy the results using
Getting Started
The best way is probably the readme file with all of the links it leads to. If you are new to AFL and/or fuzzing, there will be some learning curve. If you are new to dockers, it is worth learning about them too using online resources. If you are new to jailbreaks, iOS research, and reverse engineering, this project is probably not for you yet, but please come back when it is!